Content
Recurrent Neural Networks
Attention Mechanism
Transformer Architecture
An Introduction
by
2025-10-19
![]()
![]()
Slow to train: processing each input sequentially
Long sequences lead to vanishing gradient: its memory is not strong to interpret old connections
![]()
To overcome the vanishing gradient problem
LSTM: Long Short-Term Memory units. GRU: Gated Recurrent Units.
Memory gates: input,forget and output.
![]()
![]()

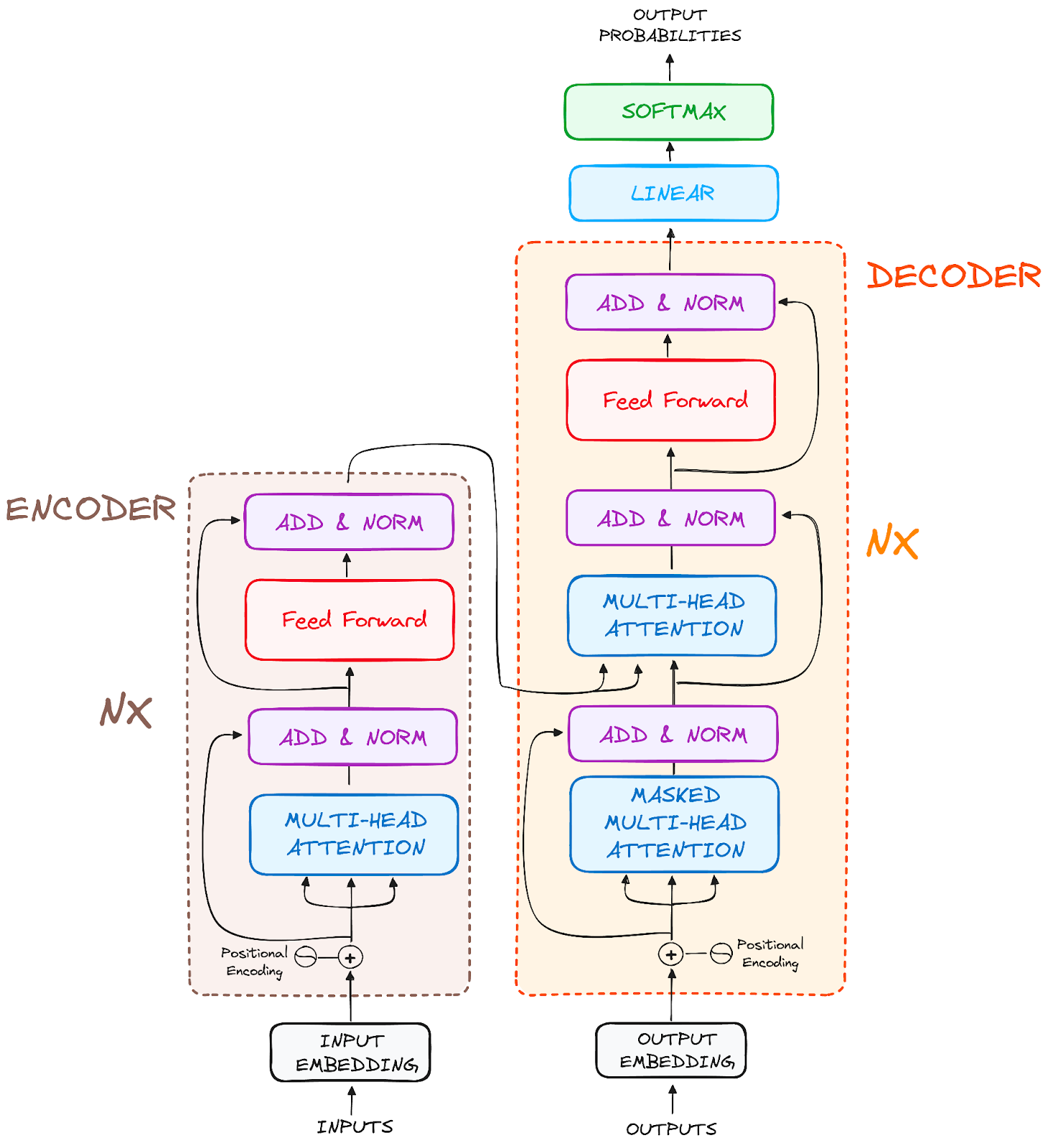
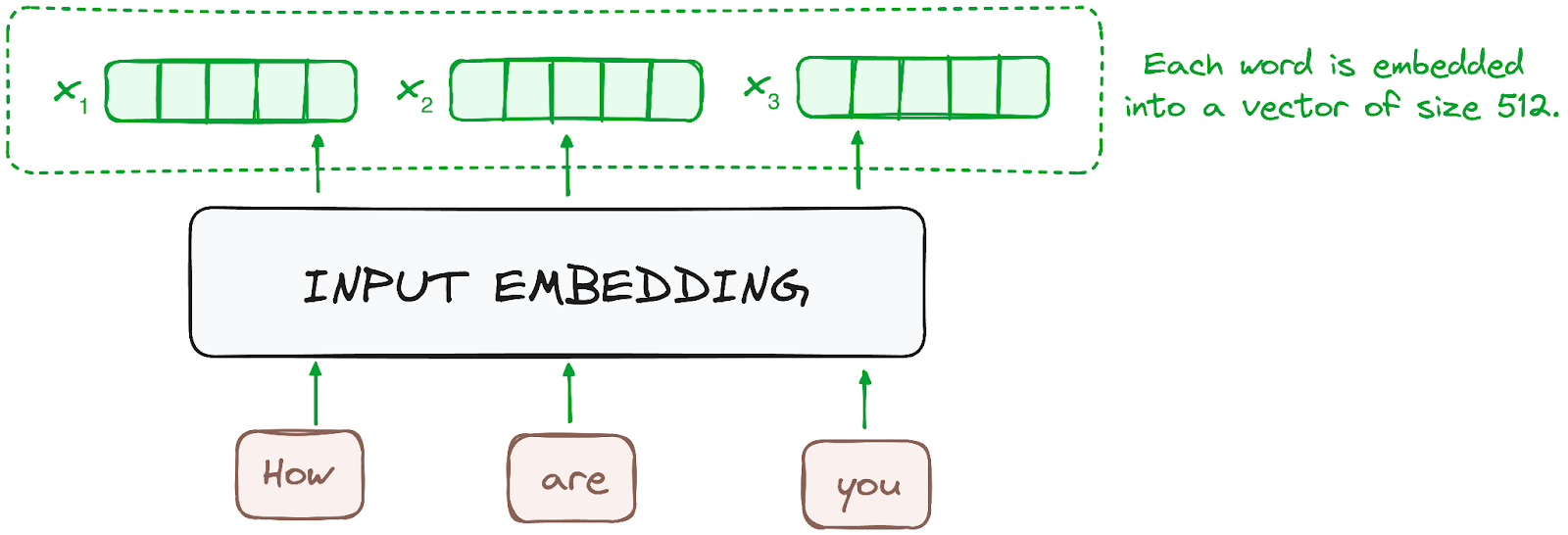
Transformers do not have recurrence mechanism like RNNs
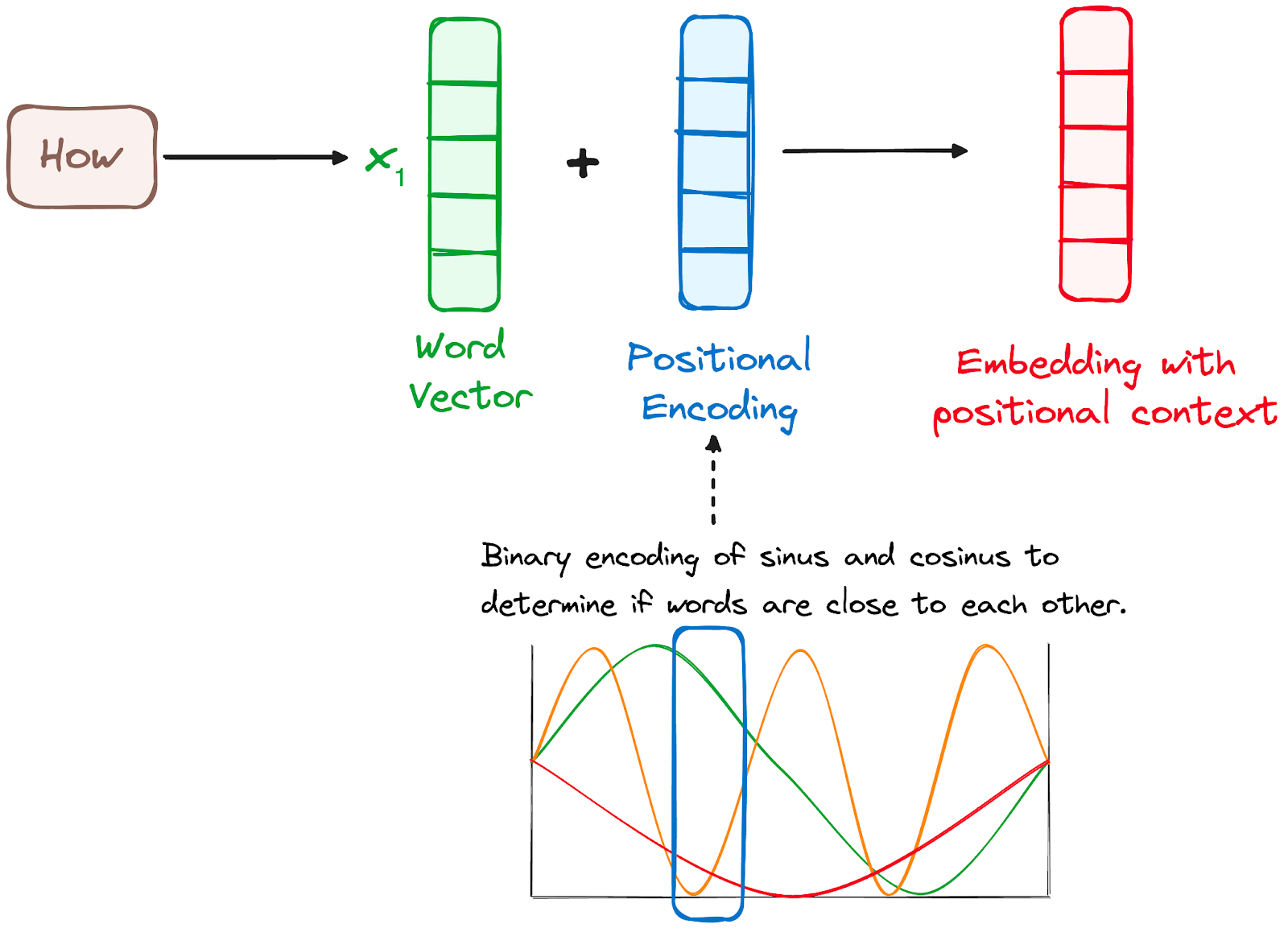
Positional encodings are added to the input embeddings to provide each token’s position information
Position vectors are generated using various sines and cosines combinations (for any sequence length)
Input tensor is split into \(h\) segments along the embedding dimension and fed to individual self-attention layer
Each attention layer uses different \(\mathbf{W}_Q,\mathbf{W}_K,\mathbf{W}_V\) matrices to capture different context like syntax, long-range dependencies and local neighbors
For additional refinement
Here also, residual connections and Layer normalization
Then the output of encoder is sent to decoder part
Overview of a single decoder layer
Each has 2 multi-headed attention mechanism but slightly different
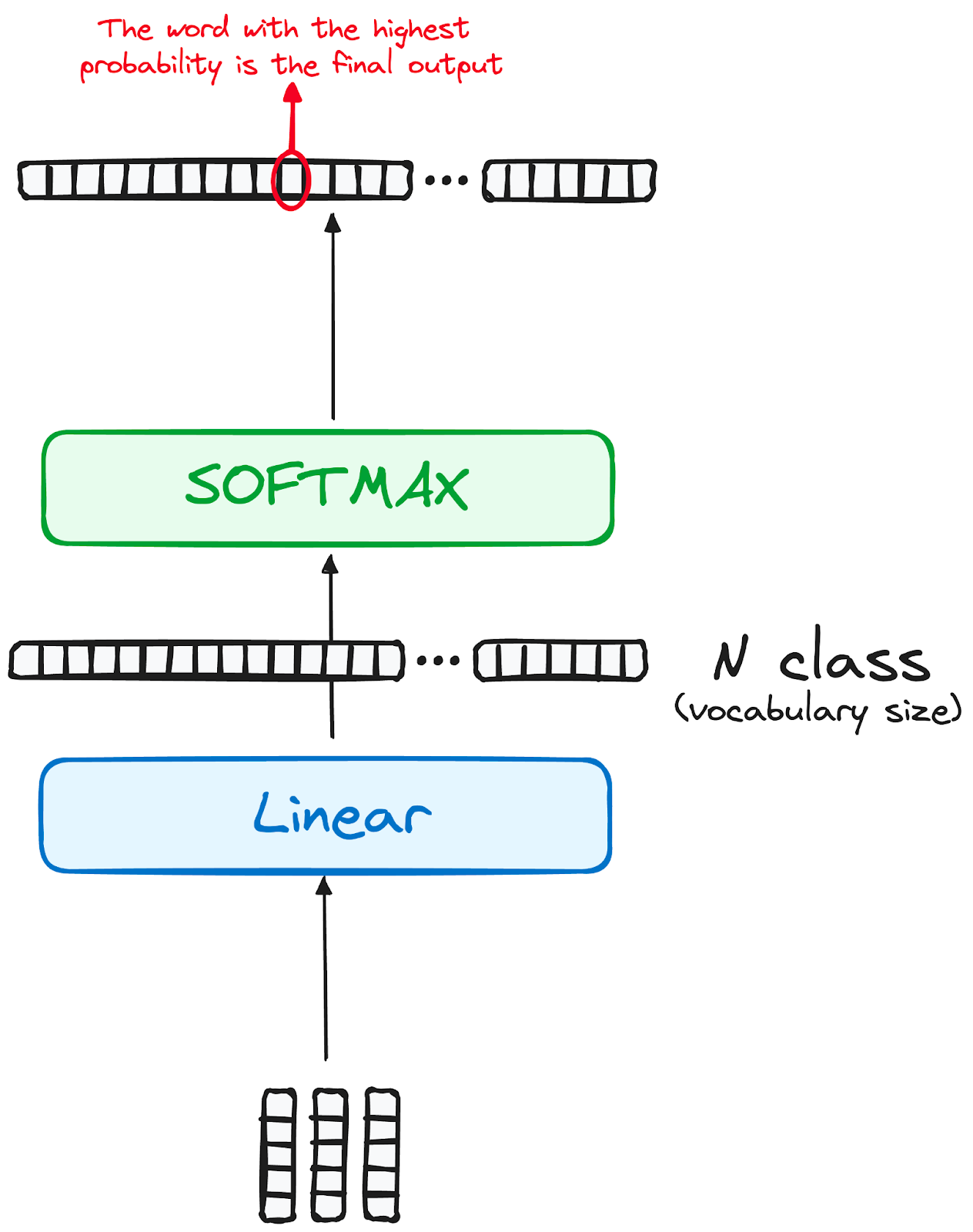
Then the output of decoder is passed through softmax layer to get probability of word that comes next
Output embedding and positional encodings are similar to that in encoder part
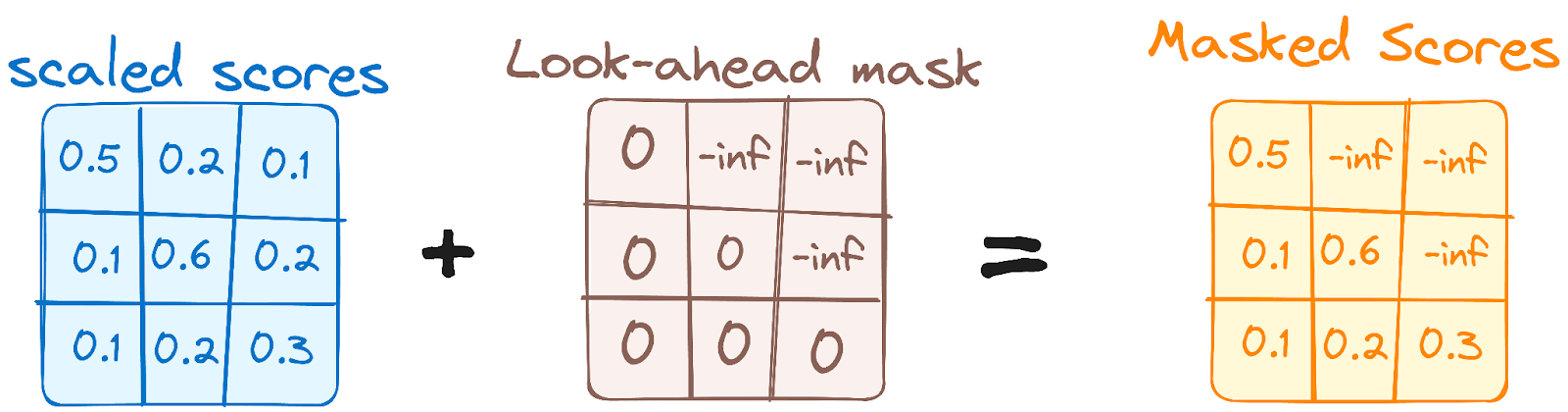
This prevents the positions/tokens from attending subsequent positions/tokens
Each has 2 multi-headed attention mechanism but slightly different
This mask ensures that the prediction for particular position is dependent only on previous positions.
This is where the input from encoder comes in.
Here, the correlation between vocabulary of two languages is determined
This will be followed by the feedforward network, where the interpretation in translation happens
The final output is passed through softmax acitvation function
It generates the probability of the next word in sequence
The probability is looked against the words in the vocabulary of second language